Cluster validation
What is cluster validation?
A process of estimating the goodness of cluster formed. That is, to ensure how accurate the obtained results of clustering.
To understand the cluster validation, consider the below figure 1 example confusion matrix obtained by the process of classification (unsupervised learning) or clustering (supervised learning).
 |
| Figure 1: Example of the confusion matrix. |
Where,
The expected result of cluster 1: CE1. The expected result of cluster 2: CE2.
The expected result of cluster 3: CE3. The expected result of cluster 4: CE4.
Obtained result of cluster 1: CO1. Obtained result of cluster 2: CO2.
Obtained result of cluster 3: CO3. Obtained result of cluster 4: CO4.
The expected result of cluster 3: CE3. The expected result of cluster 4: CE4.
Obtained result of cluster 1: CO1. Obtained result of cluster 2: CO2.
Obtained result of cluster 3: CO3. Obtained result of cluster 4: CO4.
Row: Indicates how many samples belong to a particular cluster?
Column: Indicates how many samples are placed in the cluster from which cluster?
Column: Indicates how many samples are placed in the cluster from which cluster?
Example: Arrangement of library books.
Calculating recall (recall ability) concerning:
Cluster C1:

Cluster C2:

Cluster C3:

Cluster C4:


Calculating precision concerning:
Cluster C1:

Cluster C2:

Cluster C3:

Cluster C4:

Calculating average precision :



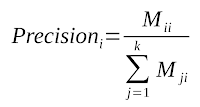 In the case of k clustering problem,
In the case of k clustering problem,














